






 แห่ง Magico อ้างว่า ลำโพงส่วนใหญ่สร้างเสียงเบสปลอม (Fake Bass) ด้วยการออกแบบอย่างที่เขาเลิกใช้ไปเมื่อ 22 ปีที่แล้ว")
")
 จากเซอร์เบีย")



 True Series : TSI-300 Stereo Integrated")


")
 Serenade for String Orchestra in E-flat major, Op. 6")

")


")



Roger Skoff writes about the real difference
Did you ever wonder how it can be possible for just two speakers to sound like an entire symphony orchestra?
Or, to turn it around, and assuming that we had the space (and the budget) for it, wouldn’t it be better if we could somehow have one dedicated speaker for each of the performers and each of the instruments on the stage at the original performance of our recorded music?
Wouldn’t it sound better with each speaker only having to reproduce just that one thing? And wouldn’t it be wonderful if we could somehow arrange those speakers in our listening room in the exact positions that the performers and instruments had been in at the original recording session? Wouldn’t that just have to “image” and “soundstage” better than only just two of even the very finest speakers?
Perhaps surprisingly, the answer is “no” on all counts. That’s simply not how either our ears, our speakers, or the recording process works:
Our ears are just organs that respond to changes in air pressure (sound) with changes in the position of their diaphragm (the eardrum), which moves back and forth as pressure levels change. Microphones are exactly the same – regardless of kind or pattern, they all have diaphragms that change position in response to changes in air pressure.
And speakers do the same thing, too, only backwards: Instead of changes in air pressure moving them, they create changes in air pressure (the sound or the music they’re reproducing) by changing the position of their diaphragm (usually a cone, dome, or ribbon) in response to a driving electrical (music) signal.

What we hear is just our brain’s interpretation of our eardrums’ changes of position, as picked up by three tiny bones in each ear and conveyed to it by our auditory nerves. And all a recording is, in the final analysis, is a record of each of those changes over a period of time.
If you stop to think about it, you’ll see that, regardless of how many things are out there producing sound (pressure waves), each eardrum (or each microphone diaphragm) can only be in one position at any given instant, and that that one position will be determined by the algebraic sum of all of the (positive and negative) pressure waves impinging on it at its specific location and that specific instant of time.

Again, with speakers, it’s exactly the same process, but in reverse: A speaker — even one in the process of reproducing the sound of the Mahler Symphony of a Thousand (Number 8 in E-flat Major) [ https://en.wikipedia.org/wiki/Symphony_No._8_(Mahler) ] with all one thousand singers and players in full tutti — can create all of it by just having one diaphragm in exactly the right place at exactly the right time.
And that’s where the issue of analog versus digital comes in: With modern digital recording, the signal from the microphone (or the mixed signals from however many microphones may be in use) is “sampled” (think of it as a snapshot of the position of the diaphragm) at least 44,100 times, and as many as 126,000 or more times a second.
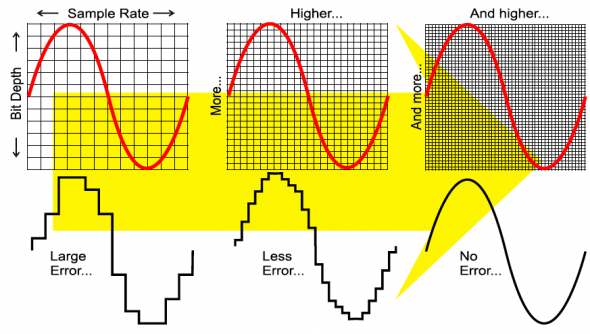
That information (diaphragm position equaling signal phase and amplitude) is then written as a number (varying in maximum size depending on the bit rate selected) that can later be read out and converted to a music signal that can be listened to and enjoyed. And, because only numbers are recorded or played back, the scratches, noise, pops, and ticks so often encountered on LP recordings are eliminated entirely.
Something about digital recording that isn’t good, however, is what’s called “stairstep” distortion. Because it’s sampled only a limited number of times and recorded with only a limited number of bits, a digital recording can never represent a truly smooth signal curve like natural music, but must always show some degree of “jumping” from one sample to the next.

Think of this as like trying to draw a picture on graph paper, where each square must either be completely filled or completely empty (equivalent to the “ones” and “zeroes” of the digital process). The bigger the squares are, the rougher any curve must be, and the smaller the squares, the smoother the curve.
If you’ll consider the height of the “squares” on a digital recording to be determined by the bit rate and the width of them to be determined by the sampling rate, you’ll understand why a low bit count (a quieter signal) and a slower sampling rate (fewer samples per second) will always make for bigger jumps (“stairsteps”) from sample to sample and a correspondingly greater amount of stairstep distortion.
I seem to recall reading, once, that at 16 bits and a 44.1kHz sampling rate, a quiet sound taking only 4 bits of recording space (like ambience sounds, for example, or pianissimo musical tones – the things that give a recording its life, detail, and soundstage – would have stairstep distortion (missing signal information) somewhere in the range of 32%! This gets less and less as the bit count and the sampling rate increase, but it’s a permanent feature of all digital recording.

Digital recording engineers mask this by injecting “dither” – essentially “white noise” – to fill the information gaps and smooth the curve. This works, but because it’s always there, regardless of the amplitude of the music signal, it serves to create an artificial “noise floor” which does improve the sound, but may also eliminate very low-level detail and some of the improved signal-to-noise ratio and greater dynamic range that digital recording has always claimed as compared to its analog counterpart.
Analog recording, on the other hand, whether on vinyl or magnetic tape, records a continuous signal, showing all of the various positions of the microphone diaphragm at every instant of time instead of just a series of samples.
Or, using that same graph paper example again, you might say that it records an infinite series of samples, but that either there are no squares on the page or the squares are so small as to be completely invisible. Either way you put it, there’s no stairstep distortion, so things like the fifth bounce of the music off the walls of the concert hall are right there to be heard, neither lost nor buried under a layer of dither.

In essence, there’s no difference at all between digital and analog recording: Both just record the position of the recording microphone’s diaphragm at a given point in time. It’s just that analog records it at infinitely more points! Even digital’s vaunted absence of ticks and pops doesn’t represent a difference in the nature of the information recorded. It’s just that analog playback is incapable of discerning the difference between recorded signal information and dust or scratches in the groove, so everything is heard.
Given all that, what’s the real difference between digital and analog? Easy: Because the effects of stairstep distortion and dithering either decline or are masked by the music at higher recording levels, digital – up to a point — tends to sound better as recoding levels get higher: In short, the louder it’s recorded, the better, clearer, and more detailed it sounds!

Analog, on the other hand, is exactly the opposite: Because of possible tape saturation, and because the mechanical elements in the disc recording and playback process (primarily the cutting head and stylus and the playback cartridge) tend to distort more as they’re worked harder, analog sounds its best, most detailed, and most “real” at lower recording levels and gets more distorted as it gets louder.
(Remember, though, that this is the level that things are recorded at, not the playback level, which can be as loud as you want, up to the point where the walls crumble or acoustic feedback sets in!)
Because even analog distortion tends to be masked by the music at higher levels and, perhaps because the kind of music I listen to tends not to be all crescendos and thunder crashes,anyway, I prefer analog.
How about you?
